White Papers

AI and machine learning workloads depend on accessing massive datasets to drive model development. However, when project teams attempt to transition pilots to production-level deployments, most discover their existing data architectures struggle to meet the performance demands.
This whitepaper discusses critical architectural considerations for optimizing data access and movement in enterprise-grade AI infrastructure. Discover:
- Common data access bottlenecks that throttle AI project productivity as workloads scale
- Why common approaches like faster storage and NAS/NFS fall short
- How Alluxio serves as a performant and scalable data access layer purpose-built for ML workloads
- Reference architecture on AWS and benchmarks test results

Explores the transformative capabilities of the Data Access Layer and how it can simplify and accelerate your analytics and AI workloads.
Kevin Petrie, VP of Research at Eckerson Group, shares the following insights in this new research paper:
- The elusive goal of analytics and AI performance
- The architecture of a Data Access Layer in the modern data stack
- The six use cases of the Data Access Layer, including analytics and AI in hybrid environments, workload bursts, cost optimization, migrations and more
- Guiding principles for making your data and AI projects successful


Kevin Petrie
VP of Research

As artificial intelligence continues to transform businesses, getting the most out of AI investments depends on solving the #1 barrier – efficient access to data1.
This technical whitepaper provides you with:
- An in-depth analysis of data access patterns at each stage of the machine learning pipeline – from ingestion to model deployment
- Strategies to optimize data flows in single vs distributed cloud environments
- Real-world examples from leading AI teams at Fintech and Internet companies
- A reference architecture to efficiently serve data to model training and model development with benchmark results
Download it now to level up your AI platform for scalability, mobility and fast data access.
[1] 2021 Gartner AI in Organizations Survey
.png)
.avif)
AI Platform and Data Infrastructure teams rely on Alluxio Data Acceleration Platform to boost the performance of data-intensive AI workloads, empower ML engineers to build models faster, and lower infrastructure costs.
With high-performance distributed cache architecture as its core, the Alluxio Data Acceleration Platform decouples storage capacity from storage performance, enabling you to more efficiently and cost-effectively grow storage capacity without worrying about performance.
- Data Acceleration
- Simplicity at Scale
- Architected for AI Workload Portability
- Lower Infrastructure Costs
In this datasheet, you will learn how Alluxio helps eliminate data loading bottlenecks and maximize GPU utilization for your AI workloads.
AI and machine learning workloads depend on accessing massive datasets to drive model development. However, when project teams attempt to transition pilots to production-level deployments, most discover their existing data architectures struggle to meet the performance demands.
This whitepaper discusses critical architectural considerations for optimizing data access and movement in enterprise-grade AI infrastructure. Discover:
- Common data access bottlenecks that throttle AI project productivity as workloads scale
- Why common approaches like faster storage and NAS/NFS fall short
- How Alluxio serves as a performant and scalable data access layer purpose-built for ML workloads
- Reference architecture on AWS and benchmarks test results
Explores the transformative capabilities of the Data Access Layer and how it can simplify and accelerate your analytics and AI workloads.
Kevin Petrie, VP of Research at Eckerson Group, shares the following insights in this new research paper:
- The elusive goal of analytics and AI performance
- The architecture of a Data Access Layer in the modern data stack
- The six use cases of the Data Access Layer, including analytics and AI in hybrid environments, workload bursts, cost optimization, migrations and more
- Guiding principles for making your data and AI projects successful
Kevin Petrie
VP of Research
As artificial intelligence continues to transform businesses, getting the most out of AI investments depends on solving the #1 barrier – efficient access to data1.
This technical whitepaper provides you with:
- An in-depth analysis of data access patterns at each stage of the machine learning pipeline – from ingestion to model deployment
- Strategies to optimize data flows in single vs distributed cloud environments
- Real-world examples from leading AI teams at Fintech and Internet companies
- A reference architecture to efficiently serve data to model training and model development with benchmark results
Download it now to level up your AI platform for scalability, mobility and fast data access.
[1] 2021 Gartner AI in Organizations Survey

A Fortune 50 technology company that serves over 1 billion users successfully implemented Alluxio to achieve a hybrid cloud strategy, become multi-cloud ready, cut costs, and boost agility.
This case study highlights:
- This tech giant’s cloud journey to modernize its data platform and the challenges it faces
- Why this company chose Alluxio to achieve hybrid and multi-cloud
- The architecture and best practices of hybrid and multi-cloud data platform architecture with Alluxio
- How Alluxio helps the company standardize the data stack and access data anywhere across all environments
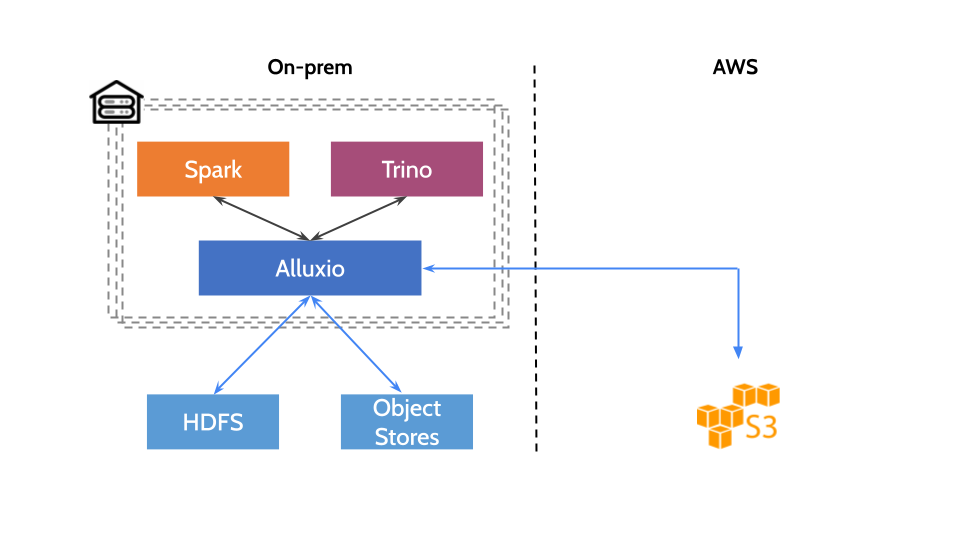
Apache Spark is an open source computation framework that supports a wide range of analytics — ETL, SQL queries, machine learning, and streaming computation. Spark’s in-memory data model and fast processing make it widely adopted by data-driven organizations.
For a global data platform, the following factors often result in slow time-to-value, high costs, and reduced agility:
- Today, data resides in silos, including data lakes, data warehouses, and object stores, whether on-premises, in the cloud, or spanning multiple geographic locations. It is challenging to find a solution that unifies data from many sources and serves it efficiently to Spark.
- An end-to-end data pipeline requires Spark to be used along with other compute frameworks like Presto, TensorFlow, etc., which requires a holistic approach to design the architecture of the data platform. Furthermore, organizations are stuck with legacy data platforms built in the pre-cloud era and lack cloud-native capabilities or require complex migrations to the cloud.
Are you seeking architectural innovation to address these challenges? Alluxio is here to help. Originating from the UC Berkeley AMPLab – the same lab as Spark, Alluxio is an open source data orchestration platform that bridges the gap between compute and storage. Alluxio empowers Spark by unifying data silos, providing data sharing across compute frameworks, and seamlessly migrating data across different environments.
By bringing Alluxio together with Spark, you can modernize your data platform in a scalable, agile, and cost-effective way. In this post, we provide an overview of the Spark + Alluxio stack. We explain the architecture, discuss real-world examples, describe deployment models, and showcase performance and cost benchmarking.
This whitepaper introduces how to speed up end-to-end distributed training in the cloud using Alluxio to accelerate data access. With the help of Alluxio, loading data from cloud storage, training and caching data can be done in a transparent and distributed way as a part of the training process. This whitepaper also demonstrates how to set up and benchmark the end-to-end performance of the training process, along with a comparison of other popular approaches.
Presto (PrestoDB and Trino) is a popular choice for organizations to run interactive analytic queries on multiple data sources at a large scale. Positioned as SQL-on-Everything, Presto is designed to be a storage-independent engine that queries against any disparate data sources anywhere.
Many organizations are constantly modernizing their data platforms and developing scalable solutions to fit their existing and future needs. Although Presto is proven to have massive data processing capabilities, it is not optimized while dealing with data access across the pipeline. As a result, data platform engineers still have to find extra solutions to eliminate data redundancy, error-prone, slow and inconsistent performance, and high costs.
To solve these challenges, an innovative architecture combining Presto with Alluxio together is recommended. Alluxio is a data orchestration platform that bridges computation frameworks and underlying storage systems. Presto and Alluxio working together enables a unified, robust, high-performance, low-latency, and cost-effective analytics architecture. This architecture not only benefits analytics but also all stages of the data pipeline, spanning ingestion, analytics, and modeling. It allows fast SQL queries across multiple storage systems on-prem, in public cloud, hybrid cloud, and multi-cloud environments.
Many companies have leveraged Alluxio to level up their current Presto platform, including Facebook, TikTok, Electronic Arts, Walmart, Tencent, Comcast, and more. They have gained significant benefits with Alluxio integrated into their Presto stack.
Alluxio started as a virtual distributed file system, a research project out of the AMPLab at U.C. Berkeley. Alluxio foresaw the need for agility when accessing large data stores separated from compute engines like Hadoop or Spark.
Fast forward several years and over a thousand committers later, and Alluxio has blossomed into the industry’s leading data orchestration platform for analytics and AI/ML. But as with any new type of technology, figuring out the best ways to use it depends on your data environment, computational workloads, issues, and goals.
So, after working with hundreds of organizations and fielding numerous inquiries, we thought it would be good to offer up a fresh take on the most popular use cases for Alluxio data orchestration.
Applications like Tensorflow, PyTorch can access data through Alluxio FUSE service without modifying any code just like accessing their local file systems by Unix/Linux POSIX API. This article describes the design and implementation of Alluxio FUSE service, its current status and future plans.
This whitepaper details how to evaluate Alluxio’s data orchestration platform as a distributed cache for Apache Spark in a public cloud or on-premises. We discuss best practices and benchmarking results with a combination of standard industry benchmarking suites, such as TPC-DS and HiBench, on cloud storage. This guide serves as a reference for reproducing similar experiments in your own environment as part of a Proof of Concept (PoC) to evaluate the use of Alluxio with Apache Spark.
This article presents the collaborative work of Alibaba, Alluxio, and Nanjing University in tackling the problem of Artificial Intelligence and Deep Learning model training in the cloud. We adopted a hybrid solution with a data orchestration layer that connects private data centers to cloud platforms in a containerized environment. Various performance bottlenecks are analyzed with detailed optimizations of each component in the architecture. Our goal for this article is to reduce the cost and complexity of data access for Deep Learning training in a hybrid environment in order to advance Deep Learning model training in the cloud.